A few months ago I started to actively study, support and use opentracing and more in general the distributed tracing topic.
In this article, I will share something about what I have learned starting from the basic I hope to get your thoughts and questions via Twitter @gianarb.
We all know the trend for the last couple of years. Spread applications across containers, cloud providers and split them into smallest units called services or microservices, pets…
This procedure brings a lot of advantages:
- you can manage people in a better way and spread them across this small units.
- small units are easy to understand for new people or after a couple of months. In a work like our where there is a high turnover having the ability to rewrite a service if nobody knows it in a couple of days it’s great.
- You can monitor these units in a better way and if you detect scalability problems or bottleneck you can stay focused on the specific problem without having other functions around. It enforces the single responsibility in some way.
Btw there are other points for sure, but the last one is very important and I think it helps us to understand why tracing is so important now.
We discover that monitor this pets is very hard and it’s different compared to the previous situation. A lot of teams discovered this complexity moving forward with services making noise in production.
Our focus is not on the virtual machine, on the hostname or the even on the container. I don’t care about the status of the server. I care about the status of the service and even deeper I care about the status of a single event in my system. This is also one of the reasons why tools like Kafka are so powerful and popular. Reply a section of your history and collect events like user registration, new invoice, new attendees register at your event, new flight booked or new article published are the most interesting part here.
Servers, containers should be replaceable things and they shouldn’t be a problem. The core here is the event. And you need to be 100% sure about having it in someplace.
Same for monitoring, if the servers, containers are not important but events are you should monitor the event and not the server.
Oh, don’t forget about distribution. It makes everything worst and more complicated my dear. Events move faster than everything else. They are across services, containers, data centers.
Where is the event? Where it failed. How a spike for particular events behave on your system? If you have too many new registrations are you still able to serve your applications?
In a big distributed environments what a particular service is calling? Or is it used? Maybe nobody is using it anymore. These questions need to have an answer.
Distributed tracing is one of the ways. It doesn’t solve all the problems but it provides a new point of view.
In practice speaking in HTTP terms tracings translate on following a specific request from its start (mobile app, web app, cronjobs, other apps) so it’s the .
Registering how many applications it crosses to, for how long. Labeling these metrics you can event understand latency between services.
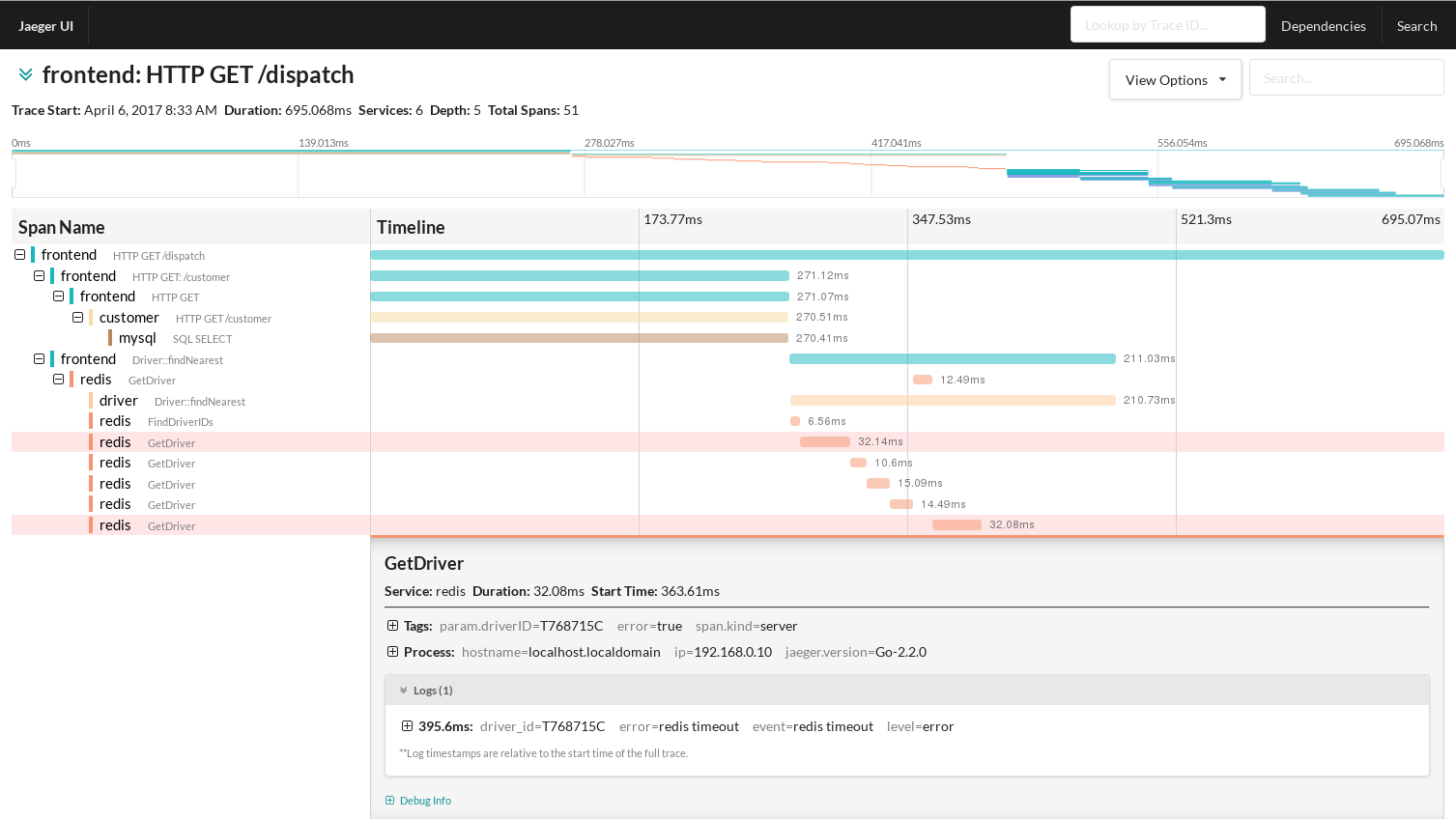 from https://www.hawkular.org/
from https://www.hawkular.org/
Speaking in the right language, this image describes a trace. It’s an HTTP to
fronted service. It’s a GET request on the /dispatch route. You can see how
far you can go. A trace is a collection of spans.
Every span has it’s own id and an optional parent id to create the hierarchy.
Spans support what is called Span Tags. It is a key-value store where the key is
always a string and some of them are “reserved” to describe specific behaviors.
You can look at them inside the specification
itselt.
Usually, UI is using this standard tag to build a nice visualization. For
example if a span contains the tag error a lot of tracers colored it red.
I suggest you read at the standard tags because it will give you the idea about how descriptive a span can be.
The architecture looks like this:
+-------------+ +---------+ +----------+ +------------+
| Application | | Library | | OSS | | RPC/IPC |
| Code | | Code | | Services | | Frameworks |
+-------------+ +---------+ +----------+ +------------+
| | | |
| | | |
v v v v
+-----------------------------------------------------+
| · · · · · · · · · · OpenTracing · · · · · · · · · · |
+-----------------------------------------------------+
| | | |
| | | |
v v v v
+-----------+ +-------------+ +-------------+ +-----------+
| Tracing | | Logging | | Metrics | | Tracing |
| System A | | Framework B | | Framework C | | System D |
+-----------+ +-------------+ +-------------+ +-----------+
from opentracing.org
There are different instrumentation libraries across multiple languages and you need to embed one of them in your application. It usually provides a global variable where you can add spans too. Time by time they are stored in the tracer that you select. If you are using Zipkin as tracer you can select different backends like ElasticSearch and Cassandra. Tracers provides API and UI to store and visualize traces.
As you can see from the graph above Opentracing “is able” to push to Tracers, Logging system, metrics and so on. With my experience with opentracing, I don’t know how this can be done.
I always used it with a Tracer like Zipkin or Jaeger to store spans. Logs are
covered by the spec because you can attach to every spans one or multiple Span
Logs.
each of which is itself a key:value map paired with a timestamp. The keys must be strings, though the values may be of any type. Not all OpenTracing implementations must support every value type.
from opentracing.org
The idea behind this feature is clear. There are too many buzzwords: metrics, logs, events, time series and now traces.
It’s easy to end up with more instrumentation libraries that business code. That’s probably why opentracing cover this uses case. Logs and traces are time series. That’s probably why metrics are there.
Using the go-sdk it looks like this:
span, ctx := opentracing.StartSpanFromContext(ctx, "operation_name")
defer span.Finish()
span.LogFields(
log.String("event", "soft error"),
log.String("type", "cache timeout"),
log.Int("waited.millis", 1500))
But I am not able to find a way to say: “Forward all these logs to ….elastic and this traces to Zipkin”. And I don’t know if the expectation is to have tracers smart enough to do that. But from my experience trying to extend Zipkin, this looks like a hard idea. At first, because the tracers are out of the OpenTracing’s scope.
If the goal is to wrap together everything logs have precise use case from ages. They work pretty well and you can’t change the expectation. They can be a real-time stream on stdout, stderr and/or other thousands of exporter. I can’t find this kind of work there. So, looking at the code it’s not clear who is in charge of what. But the graph is pretty.
I like the idea and I started looking at OpenCensus a library open sourced by Google from its experience with StackDriver and the Google’s scale. It has its specification and it provides a set of libraries that you can add to your application to get what they call stats, traces out from your app. Stat stays for metrics, events. It’s another buzz probably!
The concept looks similar to OpenTracing, obviously, the specs are different.
Looking at the code, the go-SDK looks a lot more clear. I can clearly see stats and tracing objects, they both accept exporters and they can be Prometheus, Zipkin, Jaeger, StackDriver and so on. I like the idea that the exporter is part of the project, you don’t need a tracing application like Zipkin, you can write your exporter to store data in your custom database and you are ready to go.
.
├── appveyor.yml
├── exporter
│ ├── jaeger
│ ├── prometheus
│ ├── stackdriver
│ └── zipkin
├── internal
├── plugin
├── README.md
├── stats
│ ├── internal
│ ├── ...
│ └── view
├── tag
├── trace
You can probably do the same with OpenTracing writing your tracer that store things in your custom databases jumping Zipkin and Jaeger, it looks a bit more complicated looking at the interface:
// opencensus-go/trace/export.go
// Exporter is a type for functions that receive sampled trace spans.
//
// The ExportSpan method should be safe for concurrent use and should return
// quickly; if an Exporter takes a significant amount of time to process a
// SpanData, that work should be done on another goroutine.
//
// The SpanData should not be modified, but a pointer to it can be kept.
type Exporter interface {
ExportSpan(s *SpanData)
}
// opentracing tracer
type Tracer interface {
// Create, start, and return a new Span with the given `operationName` and
// incorporate the given StartSpanOption `opts`. (Note that `opts` borrows
// from the "functional options" pattern, per
// https://dave.cheney.net/2014/10/17/functional-options-for-friendly-apis)
//
// A Span with no SpanReference options (e.g., opentracing.ChildOf() or
// opentracing.FollowsFrom()) becomes the root of its own trace.
//
StartSpan(operationName string, opts ...StartSpanOption) Span
// Inject() takes the `sm` SpanContext instance and injects it for
// propagation within `carrier`. The actual type of `carrier` depends on
// the value of `format`.
//
// OpenTracing defines a common set of `format` values (see BuiltinFormat),
// and each has an expected carrier type.
//
// Other packages may declare their own `format` values, much like the keys
// used by `context.Context` (see
// https://godoc.org/golang.org/x/net/context#WithValue).
//
Inject(sm SpanContext, format interface{}, carrier interface{}) error
// Extract() returns a SpanContext instance given `format` and `carrier`.
//
// OpenTracing defines a common set of `format` values (see BuiltinFormat),
// and each has an expected carrier type.
//
// Other packages may declare their own `format` values, much like the keys
// used by `context.Context` (see
// https://godoc.org/golang.org/x/net/context#WithValue).
//
Extract(format interface{}, carrier interface{}) (SpanContext, error)
}
OpenTracing doesn’t care about exporter and tracers, something else handle that complexity, (the user, me.. bored) the standard only offers interfaces. I don’t know if this is good. It really looks a lot more like a common interface between traces. I like the idea, but I need a lot more.
Now, writing this article I understood that I have a lot more to figure out about this projects, sadly I realized that in practice they are even more similar compared my feeling before writing all this down.
Tracing, metrics and instrumentation libraries remain crucial from my point of view. You can write everything you want but if you are not able to understand what’s happening you are not making a good job. You look like a monkey.
Personal I would like to find a common and good library to wrap together all the buzzwords stats, spans, traces, metrics, time series, logs because they are all the same concept just from a different point of view.
Everything is a point in time, grouped, ordered or with a specific hierarchy. You can use them as aggregate, to compare, to alert and so on. A powerful implementation should be able to combine both needs an easy ingestion with a clear output.
I think that OpenTracing has a lot to do from both sides in and out. OpenCensus looks good from an ingestion point of view. Nothing about logs in OpenCensus maybe because they are good enough as they are but we need to be able to cross reference logs, traces, metrics from infrastructure and application events from dashboards and automatic tools.
It looks like, with both setup, that you still need a platform capable to serve and use this data. A lot of people will answer that it’s out of scope for these projects, but I am pretty sure we all learned that just storing events is not enough.